







LinuxJournal
-
Git on Linux: A Beginner’s Guide to Version Control and Project Management

Version control is a fundamental tool in modern software development, enabling teams and individuals to track, manage, and collaborate on projects with confidence. Whether you're working on a simple script or a large-scale application, keeping track of changes, collaborating with others, and rolling back to previous versions are essential aspects of development. Among various version control systems, Git has emerged as the most widely used and trusted tool — especially on Linux, where it integrates seamlessly with the system's workflow.
This guide will walk you through the basics of Git on Linux, explaining what Git is, how to install it, and how to start using it to manage your projects efficiently. Whether you're a new developer or transitioning from another system, this comprehensive introduction will help you get started with Git the right way.
What Is Git and Why Use It?
Git is a distributed version control system (DVCS) originally created by Linus Torvalds in 2005 to support the development of the Linux kernel. It allows developers to keep track of every change made to their source code, collaborate with other developers, and manage different versions of their projects over time.
Key Features of Git:-
Distributed Architecture: Every user has a full copy of the repository, including its history. This means you can work offline and still have full version control capabilities.
-
Speed and Efficiency: Git is optimized for performance, handling large repositories and files with ease.
-
Branching and Merging: Git makes it easy to create and manage branches, allowing for efficient parallel development and experimentation.
-
Integrity and Security: Every change is checksummed and stored securely using SHA-1 hashing, ensuring that your project’s history cannot be tampered with.
Compared to older systems like Subversion (SVN) or CVS, Git offers far greater flexibility and is better suited to both small personal projects and large collaborative efforts.
Installing Git on Linux
Installing Git on Linux is straightforward thanks to package managers available in every major distribution.
For Ubuntu/Debian-based Systems:
For Fedora:sudo apt update sudo apt install git
For Arch Linux:sudo dnf install gitsudo pacman -S gitAfter installation, verify it with:
git --version -
-
Mastering Linux File Permissions and Ownership

In the world of Linux, where multi-user systems and server security are foundational principles, understanding file permissions and ownership is crucial. Whether you're a beginner exploring your first Linux distribution or a seasoned system administrator managing critical servers, knowing how permissions work is key to ensuring the integrity, privacy, and functionality of your system.
This guide will take you deep into the core of Linux file permissions and ownership—what they are, how they work, how to modify them, and why they matter.
Why File Permissions and Ownership Matter in Linux
Linux is built from the ground up as a multi-user operating system. This means:
-
Multiple users can operate on the same system simultaneously.
-
Different users have different levels of access and control.
Without a permissions system, there would be no way to protect files from unauthorized access, modification, or deletion. File permissions and ownership form the first layer of defense against accidental or malicious activity.
Linux Permission Basics: Read, Write, Execute
Each file and directory in Linux has three basic types of permissions:
-
Read (
r) – Permission to view the contents of a file or list the contents of a directory. -
Write (
w) – Permission to modify a file or create, rename, or delete files within a directory. -
Execute (
x) – For files, allows execution as a program or script. For directories, allows entering the directory (cd).
Permission Categories: User, Group, Others
Permissions are assigned to three distinct sets of users:
-
User (u) – The file's owner.
-
Group (g) – A group associated with the file.
-
Others (o) – Everyone else.
So for every file or directory, Linux evaluates nine permission bits, forming three sets of
rwx, like so:rwxr-xr--This breakdown means:
-
rwxfor the owner -
r-xfor the group -
r--for others
Understanding the Permission String
When you list files with
ls -l, you’ll see something like this:-rwxr-xr-- 1 alice developers 4096 Apr 4 14:00 script.shLet’s dissect it:
-
-
How to List Groups in Linux Like a Pro

In Linux, groups play a central role in managing user permissions and access control. Whether you're an experienced system administrator or a curious new user, understanding how to list and analyze group information is a fundamental skill. This guide explores everything you need to know about listing groups in Linux, using a variety of tools and techniques to get exactly the information you need.
What Are Groups in Linux and Why Do They Matter?
Linux is a multi-user operating system, and one of its strengths lies in the fine-grained control it offers over who can do what. Groups are a way to organize users so that multiple people can share access to files, devices, or system privileges.
Each group has:
-
A group name
-
A Group ID (GID)
-
A list of users who are members of the group
-
Primary group: Each user has one primary group defined in
/etc/passwd. Files the user creates are associated with this group by default. -
Secondary (or supplementary) groups: Users can belong to additional groups, which allow access to other resources.
How to List All Groups on a Linux System
To see every group that exists on the system, you can use the following methods:
getent groupgetent groupThis is the preferred method on modern systems because it queries the system’s name service switch configuration (NSS). It includes local and possibly remote group sources (like LDAP or NIS).
Example output:
sudo:x:27: docker:x:999:user1,user2 developers:x:1001:user3cat /etc/groupcat /etc/groupThis command prints the content of the
/etc/groupfile, which is the local group database. It’s simple and fast, but it only shows local groups.Each line is formatted as:
group_name:password_placeholder:GID:user1,user2,...compgen -g(Bash built-in)compgen -gThis command outputs only the group names, which is helpful for scripting or cleaner views.
How to List Groups for a Specific User
You might want to know which groups a particular user belongs to. Here’s how:
groups usernamegroups johnOutputs a space-separated list of groups that
johnbelongs to. If no username is given, it shows groups for the current user.id usernameid alice -
-
EU OS: A Bold Step Toward Digital Sovereignty for Europe
Image
A new initiative, called "EU OS," has been launched to develop a Linux-based operating system tailored specifically for the public sector organizations of the European Union (EU). This community-driven project aims to address the EU's unique needs and challenges, focusing on fostering digital sovereignty, reducing dependency on external vendors, and building a secure, self-sufficient digital ecosystem.
What Is EU OS?
EU OS is not an entirely novel operating system. Instead, it builds upon a Linux foundation derived from Fedora, with the KDE Plasma desktop environment. It draws inspiration from previous efforts such as France's GendBuntu and Munich's LiMux, which aimed to provide Linux-based systems for public sector use. The goal remains the same: to create a standardized Linux distribution that can be adapted to different regional, national, and sector-specific needs within the EU.
Rather than reinventing the wheel, EU OS focuses on standardization, offering a solid Linux foundation that can be customized according to the unique requirements of various organizations. This approach makes EU OS a practical choice for the public sector, ensuring broad compatibility and ease of implementation across diverse environments.
The Vision Behind EU OS
The guiding principle of EU OS is the concept of "public money – public code," ensuring that taxpayer money is used transparently and effectively. By adopting an open-source model, EU OS eliminates licensing fees, which not only lowers costs but also reduces the dependency on a select group of software vendors. This provides the EU’s public sector organizations with greater flexibility and control over their IT infrastructure, free from the constraints of vendor lock-in.
Additionally, EU OS offers flexibility in terms of software migration and hardware upgrades. Organizations can adapt to new technologies and manage their IT evolution at a manageable cost, both in terms of finances and time.
However, there are some concerns about the choice of Fedora as the base for EU OS. While Fedora is a solid and reliable distribution, it is backed by the United States-based Red Hat. Some argue that using European-backed projects such as openSUSE or KDE's upcoming distribution might have aligned better with the EU's goal of strengthening digital sovereignty.
Conclusion
EU OS marks a significant step towards Europe's digital independence by providing a robust, standardized Linux distribution for the public sector. By reducing reliance on proprietary software and vendors, it paves the way for a more flexible, cost-effective, and secure digital ecosystem. While the choice of Fedora as the base for the project has raised some questions, the overall vision of EU OS offers a promising future for Europe's public sector in the digital age.
Source: It's FOSS
-
Linus Torvalds Acknowledges Missed Release of Linux 6.14 Due to Oversight
Linus Torvalds Acknowledges Missed Release of Linux 6.14 Due to Oversight
Linux kernel lead developer Linus Torvalds has admitted to forgetting to release version 6.14, attributing the oversight to his own lapse in memory. Torvalds is known for releasing new Linux kernel candidates and final versions on Sunday afternoons, typically accompanied by a post detailing the release. If he is unavailable due to travel or other commitments, he usually informs the community ahead of time, so users don’t worry if there’s a delay.
In his post on March 16, Torvalds gave no indication that the release might be delayed, instead stating, “I expect to release the final 6.14 next weekend unless something very surprising happens.” However, Sunday, March 23rd passed without any announcement.
On March 24th, Torvalds wrote in a follow-up message, “I’d love to have some good excuse for why I didn’t do the 6.14 release yesterday on my regular Sunday afternoon schedule,” adding, “But no. It’s just pure incompetence.” He further explained that while he had been clearing up unrelated tasks, he simply forgot to finalize the release. “D'oh,” he joked.
Despite this minor delay, Torvalds’ track record of successfully managing the Linux kernel’s development process over the years remains strong. A single day’s delay is not critical, especially since most Linux users don't urgently need the very latest version.
The new 6.14 release introduces several important features, including enhanced support for writing drivers in Rust—an ongoing topic of discussion among developers—support for Qualcomm’s Snapdragon 8 Elite mobile chip, a fix for the GhostWrite vulnerability in certain RISC-V processors from Alibaba’s T-Head Semiconductor, and a completed NTSYNC driver update that improves the WINE emulator’s ability to run Windows applications, particularly games, on Linux.
Although the 6.14 release went smoothly aside from the delay, Torvalds expressed that version 6.15 may present more challenges due to the volume of pending pull requests. “Judging by my pending pile of pull requests, 6.15 will be much busier,” he noted.
You can download the latest kernel here.
-
AerynOS 2025.03 Alpha Released with GNOME 48, Mesa 25, and Linux Kernel 6.13.8
Image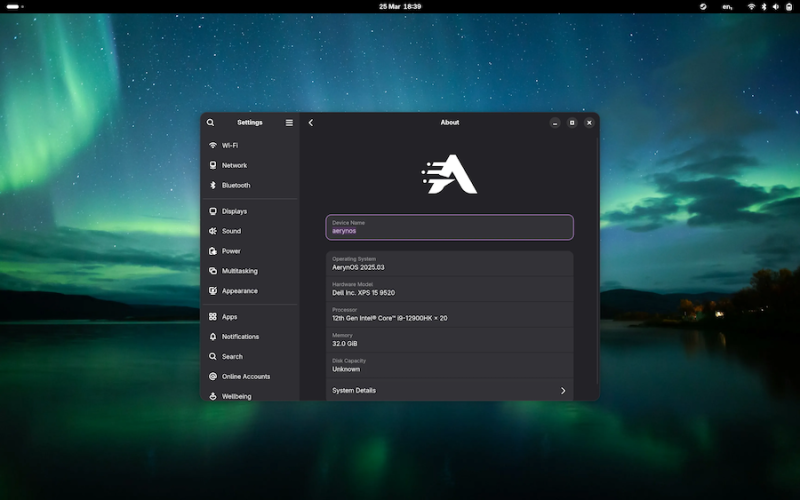
AerynOS 2025.03 has officially been released, introducing a variety of exciting features for Linux users. The release includes the highly anticipated GNOME 48 desktop environment, which comes with significant improvements like HDR support, dynamic triple buffering, and a Wayland color management protocol. Other updates include a battery charge limiting feature and a Wellbeing option aimed at improving user experience.
This release, while still in alpha, incorporates Linux kernel 6.13.8 and the updated Mesa 25.0.2 graphics stack, alongside tools like LLVM 19.1.7 and Vulkan SDK 1.4.309.0. Additionally, the Moss package manager now integrates
os-infoto generate more detailed OS metadata via a JSON file.Future plans for AerynOS include automated package updates, easier rollback management, improved disk handling with Rust, and fractional scaling enabled by default. The installer has also been revamped to support full disk wipes and dynamic partitioning.
Although still considered an alpha release, AerynOS 2025.03 can be downloaded and tested right now from its official website.
Source: 9to5Linux
-
Xojo 2025r1: Big Updates for Developers with Linux ARM Support, Web Drag and Drop, and Direct App Store Publishing
Image
Xojo has just rolled out its latest release, Xojo 2025 Release 1, and it’s packed with features that developers have been eagerly waiting for. This major update introduces support for running Xojo on Linux ARM, including Raspberry Pi, brings drag-and-drop functionality to the Web framework, and simplifies app deployment with the ability to directly submit apps to the macOS and iOS App Stores.
Here’s a quick overview of what’s new in Xojo 2025r1:
1. Linux ARM IDE Support
Xojo 2025r1 now allows developers to run the Xojo IDE on Linux ARM devices, including popular platforms like Raspberry Pi. This opens up a whole new world of possibilities for developers who want to create apps for ARM-based devices without the usual complexity. Whether you’re building for a Raspberry Pi or other ARM devices, this update makes it easier than ever to get started.
2. Web Drag and Drop
One of the standout features in this release is the addition of drag-and-drop support for web applications. Now, developers can easily drag and drop visual controls in their web projects, making it simpler to create interactive, user-friendly web applications. Plus, the WebListBox has been enhanced with support for editable cells, checkboxes, and row reordering via dragging. No JavaScript required!
3. Direct App Store Publishing
Xojo has also streamlined the process of publishing apps. With this update, developers can now directly submit macOS and iOS apps to App Store Connect right from the Xojo IDE. This eliminates the need for multiple steps and makes it much easier to get apps into the App Store, saving valuable time during the development process.
4. New Desktop and Mobile Features
This release isn’t just about web and Linux updates. Xojo 2025r1 brings some great improvements for desktop and mobile apps as well. On the desktop side, all projects now include a default window menu for macOS apps. On the mobile side, Xojo has introduced new features for Android and iOS, including support for ColorGroup and Dark Mode on Android, and a new MobileColorPicker for iOS to simplify color selection.
5. Performance and IDE Enhancements
Xojo’s IDE has also been improved in several key areas. There’s now an option to hide toolbar captions, and the toolbar has been made smaller on Windows. The IDE on Windows and Linux now features modern Bootstrap icons, and the Documentation window toolbar is more compact. In the code editor, developers can now quickly navigate to variable declarations with a simple Cmd/Ctrl + Double-click. Plus, performance for complex container layouts in the Layout Editor has been enhanced.
What Does This Mean for Developers?
Xojo 2025r1 brings significant improvements across all the platforms that Xojo supports, from desktop and mobile to web and Linux. The added Linux ARM support opens up new opportunities for Raspberry Pi and ARM-based device development, while the drag-and-drop functionality for web projects will make it easier to create modern, interactive web apps. The ability to publish directly to the App Store is a game-changer for macOS and iOS developers, reducing the friction of app distribution.
How to Get Started
Xojo is free for learning and development, as well as for building apps for Linux and Raspberry Pi. If you’re ready to dive into cross-platform development, paid licenses start at $99 for a single-platform desktop license, and $399 for cross-platform desktop, mobile, or web development. For professional developers who need additional resources and support, Xojo Pro and Pro Plus licenses start at $799. You can also find special pricing for educators and students.
Download Xojo 2025r1 today at xojo.com.
Final Thoughts
With each new release, Xojo continues to make cross-platform development more accessible and efficient. The 2025r1 release is no exception, delivering key updates that simplify the development process and open up new possibilities for developers working on a variety of platforms. Whether you’re a Raspberry Pi enthusiast or a mobile app developer, Xojo 2025r1 has something for you.
-
The Future of Linux Software: Will Flatpak and Snap Replace Native Desktop Apps?

For decades, Linux distributions have relied on native packaging formats like DEB and RPM to distribute software. These formats are deeply integrated into the Linux ecosystem, tied closely to the distribution's package manager and system architecture. But over the last few years, two newer technologies—Flatpak and Snap—have emerged, promising a universal packaging model that could revolutionize Linux app distribution.
But are Flatpak and Snap destined to replace native Linux apps entirely? Or are they better seen as complementary solutions addressing long-standing pain points? In this article, we'll explore the origins, benefits, criticisms, adoption trends, and the future of these packaging formats in the Linux world.
Understanding the Packaging Landscape
What Are Native Packages?Traditional Linux software is packaged using system-specific formats. For example:
-
.deb for Debian-based systems like Ubuntu and Linux Mint
-
.rpm for Red Hat-based systems like Fedora and CentOS
These packages are managed by package managers like
apt,dnf, orpacman, depending on the distro. They're tightly integrated with the underlying operating system, often relying on a complex set of shared libraries and system-specific dependencies.Pros of Native Packaging:
-
Smaller package sizes due to shared libraries
-
High performance and tight integration
-
Established infrastructure and tooling
Cons of Native Packaging:
-
Dependency hell: broken packages due to missing or incompatible libraries
-
Difficulty in distributing the same app across multiple distros
-
Developers must package and test separately for each distro
What Are Flatpak and Snap?
Both Flatpak and Snap aim to solve the distribution problem by allowing developers to package applications once and run them on any major Linux distribution.
Flatpak-
Developed by the GNOME Foundation
-
Focus on sandboxing and user privacy
-
Applications are installed in user space (no root needed)
-
Uses Flathub as the main app repository
Flatpak applications include their own runtime, ensuring that they work consistently across different systems regardless of the host OS's libraries.
Snap-
Developed and maintained by Canonical, the makers of Ubuntu
-
Focus on universal packaging and transactional updates
-
-
Boost Productivity with Custom Command Shortcuts Using Linux Aliases

Introduction
Linux is a powerful operating system favored by developers, system administrators, and power users due to its flexibility and efficiency. However, frequently using long and complex commands can be tedious and error-prone. This is where aliases come into play.
Aliases allow users to create shortcuts for commonly used commands, reducing typing effort and improving workflow efficiency. By customizing commands with aliases, users can speed up tasks and tailor their terminal experience to suit their needs.
In this article, we'll explore how aliases work, the different types of aliases, and how to effectively manage and utilize them. Whether you're a beginner or an experienced Linux user, mastering aliases will significantly enhance your productivity.
What is an Alias in Linux?
An alias in Linux is a user-defined shortcut for a command or a sequence of commands. Instead of typing a long command every time, users can assign a simple keyword to execute it.
For example, the command:
ls -ladisplays all files (including hidden ones) in long format. This can be shortened by creating an alias:
alias ll='ls -la'Now, whenever the user types
ll, it will executels -la.Aliases help streamline command-line interactions, minimize errors, and speed up repetitive tasks.
Types of Aliases in Linux
There are two main types of aliases in Linux:
Temporary Aliases- Exist only during the current terminal session.
- Disappear once the terminal is closed or restarted.
- Stored in shell configuration files (
~/.bashrc,~/.bash_profile, or~/.zshrc). - Persist across terminal sessions and system reboots.
Understanding the difference between temporary and permanent aliases is crucial for effective alias management.
Creating Temporary Aliases
Temporary aliases are quick to set up and useful for short-term tasks.
Syntax for Creating a Temporary Alias
Examplesalias alias_name='command_to_run'-
Shortcut for
ls -la:alias ll='ls -la' -
Quick access to
git status:alias gs='git status' -
Updating system (for Debian-based systems):
alias update='sudo apt update && sudo apt upgrade -y'
-
Essential Tools and Frameworks for Mastering Ethical Hacking on Linux

Introduction
In today's digital world, cybersecurity threats are ever-growing, making ethical hacking and penetration testing crucial components of modern security practices. Ethical hacking involves legally testing systems, networks, and applications for vulnerabilities before malicious hackers can exploit them. Among the various operating systems available, Linux has established itself as the preferred choice for ethical hackers due to its flexibility, security, and extensive toolkit.
This article explores the most powerful ethical hacking tools and penetration testing frameworks available for Linux users, providing a guide to help ethical hackers and penetration testers enhance their skills and secure systems effectively.
Understanding Ethical Hacking and Penetration Testing
What is Ethical Hacking?Ethical hacking, also known as penetration testing, is the practice of assessing computer systems for security vulnerabilities. Unlike malicious hackers, ethical hackers follow legal and ethical guidelines to identify weaknesses before cybercriminals can exploit them.
Difference Between Ethical Hacking and Malicious Hacking
The Five Phases of Penetration TestingEthical Hacking Malicious Hacking Authorized and legal Unauthorized and illegal Aims to improve security Aims to exploit security flaws Conducted with consent Conducted without permission Reports vulnerabilities to system owners Exploits vulnerabilities for personal gain -
Reconnaissance – Gathering information about the target system.
-
Scanning – Identifying active hosts, open ports, and vulnerabilities.
-
Exploitation – Attempting to breach the system using known vulnerabilities.
-
Privilege Escalation & Post-Exploitation – Gaining higher privileges and maintaining access.
-
Reporting & Remediation – Documenting findings and suggesting fixes.
Now, let's explore the essential tools used by ethical hackers and penetration testers.
Essential Ethical Hacking Tools for Linux
Reconnaissance & Information GatheringThese tools help gather information about a target before launching an attack.
-
Nmap (Network Mapper) – A powerful tool for network scanning, host discovery, and port scanning.
-